
机器学习|多项式回归算法详解
多项式回归介绍
在线性回归中,我们通过建立自变量 x 的一次方程来拟合数据。而非线性回归中,则需要建立因变量和自变量之间的非线性关系。从直观上讲,也就是拟合的直线变成了「曲线」。
如下图所示,是某地区人口数量的变化数据。如果我们使用线性方差去拟合数据,那么就会存在「肉眼可见」的误差。而对于这样的数据,使用一条曲线去拟合则更符合数据的发展趋势。
对于非线性回归问题而言,最简单也是最常见的方法就是本次实验要讲解的「多项式回归」。多项式是中学时期就会接触到的概念,这里引用 维基百科 的定义如下:
多项式(Polynomial)是代数学中的基础概念,是由称为未知数的变量和称为系数的常量通过有限次加法、加减法、乘法以及自然数幂次的乘方运算得到的代数表达式。多项式是整式的一种。未知数只有一个的多项式称为一元多项式;例如 $x^2-3x+4$ 就是一个一元多项式。未知数不止一个的多项式称为多元多项式,例如 $x^3-2xyz^2+2yz+1$ 就是一个三元多项式。
多项式回归基础
首先,我们通过一组示例数据来认识多项式回归
1 | # 加载示例数据 |
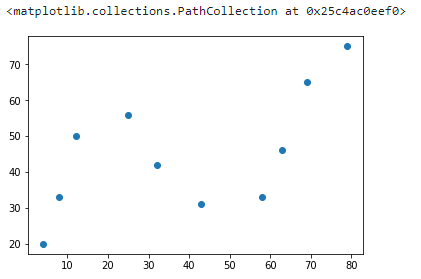
示例数据一共有 10 组,分别对应着横坐标和纵坐标。接下来,通过 Matplotlib 绘制数据,查看其变化趋势。
1 | %matplotlib inline |
实现 2 次多项式拟合
接下来,通过多项式来拟合上面的散点数据。首先,一个标准的一元高阶多项式函数如下所示:
$$
y(x, w) = w_0 + w_1x + w_2x^2 +…+w_mx^m = \sum\limits_{j=0}^{m}w_jx^j \tag{1}
$$
其中,m 表示多项式的阶数,x^j 表示 x 的 j 次幂,w 则代表该多项式的系数。
当我们使用上面的多项式去拟合散点时,需要确定两个要素,分别是:多项式系数 $w$ 以及多项式阶数 $m$,这也是多项式的两个基本要素。
如果通过手动指定多项式阶数 $m$ 的大小,那么就只需要确定多项式系数 $w$ 的值是多少。例如,这里首先指定 $m=2$,多项式就变成了:
$$
y(x, w) = w_0 + w_1x + w_2x^2= \sum\limits_{j=0}^{2}w_jx^j \tag{2}
$$
当我们确定 $w$ 的值的大小时,就回到了前面线性回归中学习到的内容。
首先,我们构造两个函数,分别是用于拟合的多项式函数,以及误差函数。
1 | """实现 2 次多项式函数及误差函数 |
接下来,使用 NumPy 提供的随机数方法初始化 3 个 $w$ 参数
1 | import numpy as np |
1 | array([ 0.60995017, 1.32614407, -1.22657863]) |
接下来,就是使用最小二乘法求解最优参数的过程。这里为了方便,我们直接使用 Scipy 提供的最小二乘法类,得到最佳拟合参数。当然,你完全可以按照线性回归实验中最小二乘法公式自行求解参数。不过,实际工作中为了快速实现,往往会使用像 Scipy 这样现成的函数,这里也是为了给大家多介绍一种方法。
1 | """使用 Scipy 提供的最小二乘法函数得到最佳拟合参数 |
关于
scipy.optimize.leastsq()的具体使用介绍,可以阅读 官方文档。
1 | Fitting Parameters: [ 3.76893126e+01 -2.60474221e-01 8.00078171e-03] |
我们这里得到的最佳拟合参数 $w_0$, $w_1$, $w_2$ 依次为 3.76893117e+01, -2.60474147e-01 和 8.00078082e-03。也就是说,我们拟合后的函数(保留两位有效数字)为:
$$
y(x) = 37 - 0.26x + 0.0080x^2 \tag{3}
$$
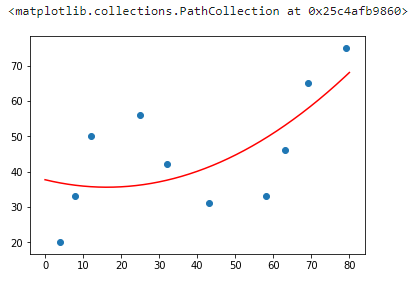
然后,我们尝试绘制出拟合后的图像。
1 | """绘制 2 次多项式拟合图像 |
实现 N 次多项式拟合
你会发现,上面采用 2 次多项式拟合的结果也不能恰当地反映散点的变化趋势。此时,我们可以尝试 3 次及更高次多项式拟合。接下来的代码中,我们将针对上面 2 次多项式拟合的代码稍作修改,实现一个 N 次多项式拟合的方法。
1 | """实现 n 次多项式拟合 |
可以使用 n=3 验证一下上面的代码是否可用。
1 | n_poly(3) |
1 | array([ 8.00077828e-03, -2.60473932e-01, 3.76893089e+01]) |
此时得到的参数结果和公式(3)的结果一致,只是顺序有出入。这是因为 NumPy 中的多项式函数 np.poly1d(3) 默认的样式是:
$$
y(x) = 0.0080x^2 - 0.26x + 37\tag{4}
$$
接下来,我们绘制出 4,5,6,7, 8, 9 次多项式的拟合结果。
1 | """绘制出 4,5,6,7, 8, 9 次多项式的拟合图像 |
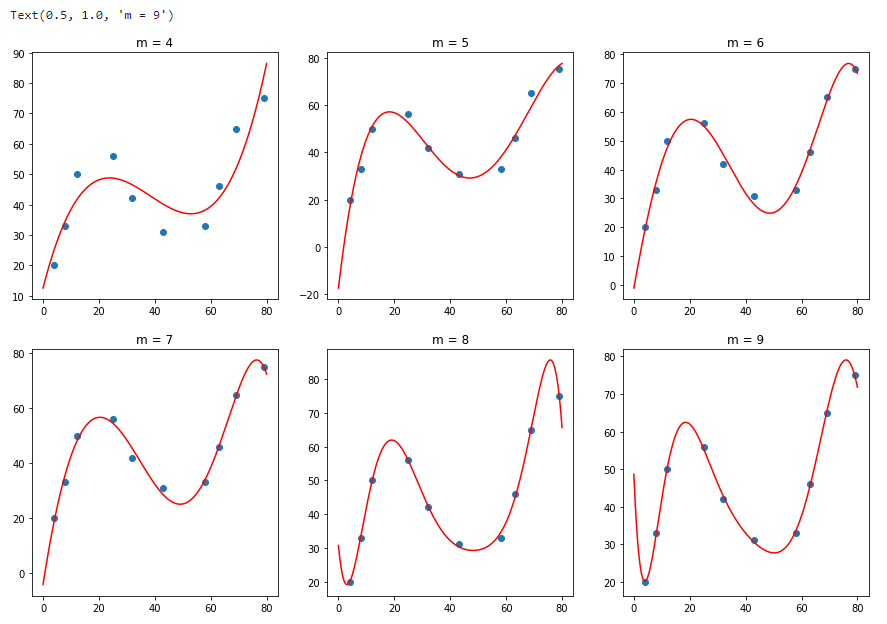
从上面的 6 张图可以看出,当 m=4(4 次多项式) 时,图像拟合的效果已经明显优于 m=3 的结果。但是随着 m 次数的增加,当 m=8 时,曲线呈现出明显的震荡,这也就是线性回归实验中所讲到的过拟和(Overfitting)现象。
使用 scikit-learn 进行多项式拟合
除了像上面我们自己去定义多项式及实现多项式回归拟合过程,也可以使用 scikit-learn 提供的多项式回归方法来完成。这里,我们会用到sklearn.preprocessing.PolynomialFeatures() 这个类。PolynomialFeatures() 主要的作用是产生多项式特征矩阵。如果你第一次接触这个概念,可能需要仔细理解下面的内容。
对于一个二次多项式而言,我们知道它的标准形式为:$ y(x, w) = w_0 + w_1x + w_2x^2 $。但是,多项式回归却相当于线性回归的特殊形式。例如,我们这里令 $x = x_1$, $x^2 = x_2$ ,那么原方程就转换为:$ y(x, w) = w_0 + w_1x_1 + w_2x_2 $,这也就变成了多元线性回归。这就完成了一元高次多项式到多元一次多项式之间的转换。
举例说明,对于自变量向量 $X$ 和因变量 $y$,如果 $X$:
$$
\mathbf{X} = \begin{bmatrix}
2 \[0.3em]
-1 \[0.3em]
3
\end{bmatrix} \tag{5a}
$$
我们可以通过 $ y = w_1 x + w_0$ 线性回归模型进行拟合。同样,如果对于一元二次多项式 $ y(x, w) = w_0 + w_1x + w_2x^2 $,如果能得到由 $x = x_1$, $x^2 = x_2$ 构成的特征矩阵,即:
$$
\mathbf{X} = \left [ X, X^2 \right ] = \begin{bmatrix}
2& 4\ -1
& 1\ 3
& 9
\end{bmatrix}
\tag{5b}
$$
那么也就可以通过线性回归进行拟合了。
你可以手动计算上面的结果,但是当多项式为一元高次或者多元高次时,特征矩阵的表达和计算过程就变得比较复杂了。例如,下面是二元二次多项式的特征矩阵表达式。
$$
\mathbf{X} = \left [ X_{1}, X_{2}, X_{1}^2, X_{1}X_{2}, X_{2}^2 \right ]
\tag{5c}
$$
还好,在 scikit-learn 中,我们可以通过 PolynomialFeatures() 类自动产生多项式特征矩阵,PolynomialFeatures() 类的默认参数及常用参数定义如下:
1 | sklearn.preprocessing.PolynomialFeatures(degree=2, interaction_only=False, include_bias=True) |
degree: 多项式次数,默认为 2 次多项式interaction_only: 默认为 False,如果为 True 则产生相互影响的特征集。include_bias: 默认为 True,包含多项式中的截距项。
对应上面的特征向量,我们使用 PolynomialFeatures() 的主要作用是产生 2 次多项式对应的特征矩阵,如下所示:
1 | """使用 PolynomialFeatures 自动生成特征矩阵 |
1 | array([[ 2., 4.], |
对于上方单元格中的矩阵,第 1 列为 $X^1$,第 2 列为 $X^2$。我们就可以通过多元线性方程 $ y(x, w) = w_0 + w_1x_1 + w_2x_2 $ 对数据进行拟合。
注意:本篇文章中,你会看到大量的
reshape操作,它们的目的都是为了满足某些类传参的数组形状。这些操作在本实验中是必须的,因为数据原始形状(如上面的一维数组)可能无法直接传入某些特定类中。但在实际工作中并不是必须的,因为你手中的原始数据集形状可能支持直接传入。所以,不必为这些reshape操作感到疑惑,也不要死记硬背。
回到 2.1 小节中的示例数据,其自变量应该是 $x$,而因变量是 $y$。如果我们使用 2 次多项式拟合,那么首先使用 PolynomialFeatures() 得到特征矩阵。
1 | """使用 sklearn 得到 2 次多项式回归特征矩阵 |
1 | array([[4.000e+00, 1.600e+01], |
可以看到,输出结果正好对应一元二次多项式特征矩阵公式:$\left [ X, X^2 \right ]$
然后,我们使用 scikit-learn 训练线性回归模型。这里将会使用到 LinearRegression() 类,LinearRegression() 类的默认参数及常用参数定义如下:
1 | sklearn.linear_model.LinearRegression(fit_intercept=True, normalize=False, copy_X=True, n_jobs=1) |
fit_intercept: 默认为 True,计算截距项。normalize: 默认为 False,不针对数据进行标准化处理。copy_X: 默认为 True,即使用数据的副本进行操作,防止影响原数据。n_jobs: 计算时的作业数量。默认为 1,若为 -1 则使用全部 CPU 参与运算。
1 | """转换为线性回归预测 |
1 | (array([2.13162821e-14]), array([[1.00000000e+00, 4.35999447e-18]])) |
你会发现,这里得到的参数值和公式(3),(4)一致。为了更加直观,这里同样绘制出拟合后的图像。
1 | """绘制拟合图像 |
你会发现,上图似曾相识。它和公式(3)下方的图其实是一致的。






