
译|Bayesian Personalized Ranking with Multi-Channel User Feedback
已经显示$learning−to−rank$算法允许推荐系统利用一元用户进行反馈。我们提出了$Multi−feedback$ $Bayesian$ $Personalized$ $Ranking$(多反馈贝叶斯个性化排序),即利用扩展采样与不同类型反馈的成对方法。反馈类型来自不同的$channels$,其中$users$与$items$相互作用$(e.g.,clicks,likes,listens,follows,andpurchase)$。我们通过像$clicks$,$likes$这样不同类型的反馈,来反映不同级别的$commitment$或$preference$。我们的方法不同之处在于它在训练过程中同时利用多个反馈来源,$MF−BPR$的新颖之处在于它是一种扩展的采样方法, 将反馈源等同于信号预期贡献的$level$。我们通过对包含多种反馈类型的三个数据集进行了一系列实验来证明我们的方法的有效性,实验结果表明:采用更好采样方法的$MF−BPR$在准确性方面优于$BPR$,$MF−BPR$的优势在于它能够在抽样负面项目时利用水平信息。
INTRODUCTION
在许多领域,用户通过许多不同的 channels$channels$ 提供一元反馈。例如,在线市场收集视图,添加到购物车和购买信号,音乐平台记录收听,收藏和添加播放列表事件。贝叶斯个性化排名,一种通过抽样对学习用户偏好的成对学习-排名方法,允许推荐系统有效地从一元反馈中学习。然而,目前 BPR$BPR$ 的实例化不能充分利用某些领域中可用的所有不同类型的反馈。
在本文中,我们提出了一种称为 MF−BPR$MF-BPR$ 的方法。 MF−BRP$MF−BRP$ 的创新是旨在同时训练期间利用来自多个渠道的一元反馈一种采样方法,这种采样方法已经被证明可有效改善 BPR$BPR$。
我们方法的关键是将不同的反馈渠道映射到不同的 levels$levels$,以反映每种类型的反馈在培训阶段可能产生的 contribution$contribution$。在 BPR$BPR$ 样本对中第一项优先于第二项,而 MF−BPR$MF-BPR$ 的 levels$levels$ 有助于自动引导采样,将重点放在信息量最大的样本对中。该方法的优点在于它利用可用信息的一致性和一些用户反馈信号比其他信号更可靠或更有意义的直观判断。
本文的结构如下:在下一节中,我们将介绍相关的相关工作。然后,我们详细介绍 MF−BPR$MF-BPR$ 和我们测试的三个数据集。之后对实验结果进行说明,这些结果证明了 MF−BPR$MF-BPR$ 改善 BPR$BPR$ 的能力。最后,我们结束对结果的讨论,该结果揭示了通过对项目对的 negative$negative$ 项目的合理取样所带来的改进。
RELATED WORK
自 BPR$BPR$ 引入以来,已经提出了许多改进,MF−BPR$MF-BPR$ 属于对抽样进行改进的方法。这方面的最初贡献是由 [3] 做出的,他们通过流行度对项目抽样进行加权。最近,[7] 提出了自适应采样,它基于当前模型对信息对进行过采样。MF−BPR$MF-BPR$ 类似于这种方法,侧重于信息对,但其采样是由反馈信道 feedbackchannels$feedbackchannels$ 所驱动的。在本节的剩余部分,我们将介绍已经提出的利用来自不同源的反馈的各种技术,为每个关键点提供示例并并标注与 MF−BPR$MF-BPR$ 的差异。
矩阵分解方法试图同时分解多个矩阵,[11] 的作者考虑了来自社交网络(评论,重新分享或创建帖子)的不同信号,这些信号具有单独的分解因式,用于进行随后组合的预测。[4] 的工作利用了多种类型的关系,并针对冷启动问题。而 MF−BPR$MF-BPR$ 的 “多“ 指的是反映相同用户-项目关系的多种类型的反馈。
其他方法使用了 ratings$ratings$ 表示不同层次的用户反馈的方法。在 [9] 中提出了列表优化标准,其允许 learning−to−rank$learning−to−rank$ 算法利用分级反馈。与我们的工作最密切相关的是 [5],它使用 ratings$ratings$ 和 interactioncounts$interactioncounts$ 衍生分级隐式反馈的 BPR$BPR$ 算法,同时还探讨了时间信息的 contribution$contribution$。本文展望了混合方法的发展前景,MF−BPR$MF-BPR$ 可以被视为混合型,因为它同时使用不同的反馈源,它与 [5] 的不同之处在于它避免了手动选择的权重,更重要的是,它同时使用多个反馈通道。
MULTI-FEEDBACK BPR
BPR−MF$BPR-MF$ 基于以下见解:通过各种渠道收集的用户反馈反映了用户偏好的不同优势,BPR$BPR$的抽样方法可以利用这些差异。简而言之,我们允许 BPR$BPR$ 从以下事实中学习:例如,点击代表不同程度的 commitment$commitment$ 或 preference$preference$ 类似于 like$like$。
对于由给定训练集 S$S$ 组成的 user−item$user−item$ 对 (u,i)$(u,i)$,标准 BPR$BPR$ 通过从 S$S$ 中采集观察到的反馈对 (u,i)$(u,i)$ 来创建元组 (u,i,j)$(u,i,j)$,其中 negativeitem$negativeitem$j$j$ 表示 u$u$ 中未观察到的项目。对于每个采样元组,BPR$BPR$ 算法以随机梯度下降的方式更新参数,使得 i$i$ 的排名高于 j$j$,MF−BPR$MF-BPR$ 则将不同类型的反馈映射到 levels$levels$ 上,这允许我们约束抽样以反映我们与反馈类型相关联的偏好程度 (preferencestrengths)$(preferencestrengths)$。图1将标准 BPR$BPR$ 采样方法(A)$(A)$与 MF−BPR$MF-BPR$ 使用的扩展采样方法(B)$(B)$进行了比较,后者对正反馈的类型施加了一个顺序,这使得在学习阶段可用的反馈之间存在更细微的差异。
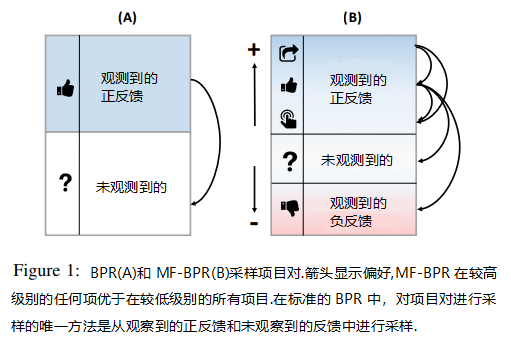
现在我们将正式介绍 MF−BPR$MF-BPR$ 如何利用反馈 levels$levels$。令 L=(L1,…,Lp)$L=(L1,…,Lp)$ 表示数据集中给定的有序 levels$levels$ 集合,使得与 Li+1$Li+1$ 中的反馈相比,Li$Li$中反馈的 interest$interest$ 信号更强,即 Li≻Li+1$Li≻Li+1$。 一般来说,未观察到的反馈也被认为属于 Luo$Luo$,因此对于每个正反馈级别 Li$Li$ 和负反馈级别 Lj$Lj$ ,有 Li≻Luo$Li≻Luo$ 和 Luo≻Lj$Luo≻Lj$。级别 L$L$ 的训练反馈集由 SL$SL$表示。我们将 L+$L+$ 和 L−$L−$ 定义为正反馈水平和负反馈水平。在标准 BPR$BPR$中,因为 |L|=2$|L|=2$,∣∣L+∣∣=1$|L+|=1$ 和 ∣∣L−∣∣=0$|L−|=0$,对于未观察到的反馈,只有一个级别的正反馈,而另一个级别没有明确的负反馈。我们还将 IL,u$IL,u$ 定义为用户 u$u$ 与之交互的级别 L$L$ 中的项目,将 Iu$Iu$ 定义为 u$u$ 与之交互的所有项目(在所有级别中)。MF−BPR$MF-BPR$ 的 DMF$DMF$ 中所有首选项组合的集合可以定义为:
DMF={(u,i,j)|i∈IL,u∧j∈IN,u∧L∈L+∧L≻N}(1)
$$(1)DMF={(u,i,j)|i∈IL,u∧j∈IN,u∧L∈L+∧L≻N}$$
在标准 BPR$BPR$ 中,元组(u,i,j)$(u,i,j)$被均匀地采样,但是在 MF−BPR$MF-BPR$ 中,我们引入了非均匀采样器,其考虑了反馈信道的层次(重要性)。要使用多个级别,MF−BPR$MF-BPR$ 需要从 L$L$ 采样 L$L$ 和 N$N$,然后可以相对于给定级别对元组(u,i,j)$(u,i,j)$进行采样。通过对 S$S$ 使用采样分布 p(u,i,L)$p(u,i,L)$ 抽样观察反馈来对 positiveitem$positiveitem$ 采样,同时也对 positivelevelL$positivelevelL$ 进行采样。概率分布 p(u,i,L)$p(u,i,L)$ 可以进一步扩展为 p(u,i,L)=p(u,i|L)p(L)$p(u,i,L)=p(u,i|L)p(L)$,使得 p(u,i|L)$p(u,i|L)$ 是均匀分布在 SL$SL$ 和 p(L)$p(L)$ 上的 L$L$ 级采样分布。p(L)$p(L)$ 的一个简单选择是在所有级别上的均匀分布。然而,如果分布均匀,基数较小的 levels$levels$ 将被过采样,这可能导致采样不良。我们提出了非均匀分布的 p(L)$p(L)$,其中反馈的基数以及 levels$levels$ 的重要性与权重因子一起考虑。概率分布 p(L)$p(L)$ 定义为:
p(L)=wL|SL|∑Q∈L+wQ∣∣SQ∣∣(2)
$$(2)p(L)=wL|SL|∑Q∈L+wQ|SQ|$$
其中,wL$wL$ 是等级 L$L$ 的权重。在权重相等的情况下,从所有级别均匀地对正项进行采样,这相当于标准 BPR$BPR$ 的正采样器。可以定义非均匀分布的权重值以反映 levels$levels$ 的重要性。在实验中,我们发现正 levels$levels$ 的逆是权重的良好候选者(即w1=1,w2=12,…)$(即w1=1,w2=12,…)$。如果 levels$levels$ 的顺序不是已知的先验(例如,是否应该认为 like$like$ 比 share$share$ 更重要,反之亦然),则可以通过使用超参数搜索算法来寻找近似最佳权重。
要对负项目 j$j$ 进行采样,应该给出正项目的级别以便采样器从其下面的一个级别中采样项目。给定正 levelL$levelL$ 和正 user−item$user−item$ 对 (u,i)$(u,i)$,我们将采样分布 p(j,N|u,L)$p(j,N|u,L)$ 表示为负样本 j$j$ 及其对应的 levelN$levelN$。与正采样器类似,负采样器可以扩展为 p(j,N|u,L)=p(j|u,L,N)p(N|u,L)$p(j,N|u,L)=p(j|u,L,N)p(N|u,L)$ 其中 p(j|u,L,N)$p(j|u,L,N)$是负项目采样器,p(N|u,L)$p(N|u,L)$ 是条件负级采样器。我们还提出了一个非均匀的负项目采样器类似于(2),它考虑了基数和基数的权重。 negativelevel$negativelevel$ 采样器 p(N|u,L)$p(N|u,L)$ 定义为:
p(N|u,L)=⎧⎨⎩(1−β)wN|SN|∑Q≻LwQ∣∣SQ∣∣N≠LuoβN=Luo(3)
$$(3)p(N|u,L)={(1−β)wN|SN|∑Q≻LwQ|SQ|N≠LuoβN=Luo$$
0≤β≤1$0≤β≤1$ 是控制采样中未观察到的反馈的比率的参数。对于标准 BPR$BPR$ β=1$β=1$ 是因为所有负项目都是从未观察到的反馈中采样的,正确 β$β$ 值可以通过实验得到。在实验中,我们发现在 β$β$ 值较高的情况下模型更准确。关于对 β$β$ 正确值的观察将在第4节中更详细地讨论。
与标准 BPR$BPR$ 类似,如果 N≠Luo$N≠Luo$ 则负采样器 p(j|u,L,N)$p(j|u,L,N)$ 可以从 IN,u$IN,u$ 均匀地对负项目采样,如果 N=Luo$N=Luo$,则可以从 I∖Iu$I∖Iu$ 采样。我们将 puni(j|u,L,N)$puni(j|u,L,N)$ 表示为统一负项目采样器,定义为:
puni(j|u,L,N)=⎧⎪ ⎪ ⎪⎨⎪ ⎪ ⎪⎩1∣∣IN,u∣∣N≠Luo∧j∈IN,u1|I∖Iu|N=Luo∧j∈I∖Iu0 otherwise (4)
$$(4)puni(j|u,L,N)={1|IN,u|N≠Luo∧j∈IN,u1|I∖Iu|N=Luo∧j∈I∖Iu0 otherwise $$
此外,当 N$N$ 是未观察到的等级 Luo$Luo$ 时,我们还提出了提出一个带有非均匀采样器的多级项目采样器。将多级负项目采样器 pml(j|u,L,N)$pml(j|u,L,N)$ 定义为:
pml(j|u,L,N)=⎧⎪ ⎪⎨⎪ ⎪⎩1∣∣IN,u∣∣N≠Luo∧j∈IN,up(j,u′,L′|u)N=Luo∧j∈I∖Iu0 otherwise (5)
$$(5)pml(j|u,L,N)={1|IN,u|N≠Luo∧j∈IN,up(j,u′,L′|u)N=Luo∧j∈I∖Iu0 otherwise $$
译|Bayesian Personalized Ranking with Multi-Channel User Feedback
http://blog.laugh12321.cn/2019/07/15/bpr_with_multi-channel_user_feedback/





